Recipes
A recipe is the main configuration file for metadata ingestion. It tells our ingestion scripts where to pull data from (source) and where to put it (sink).
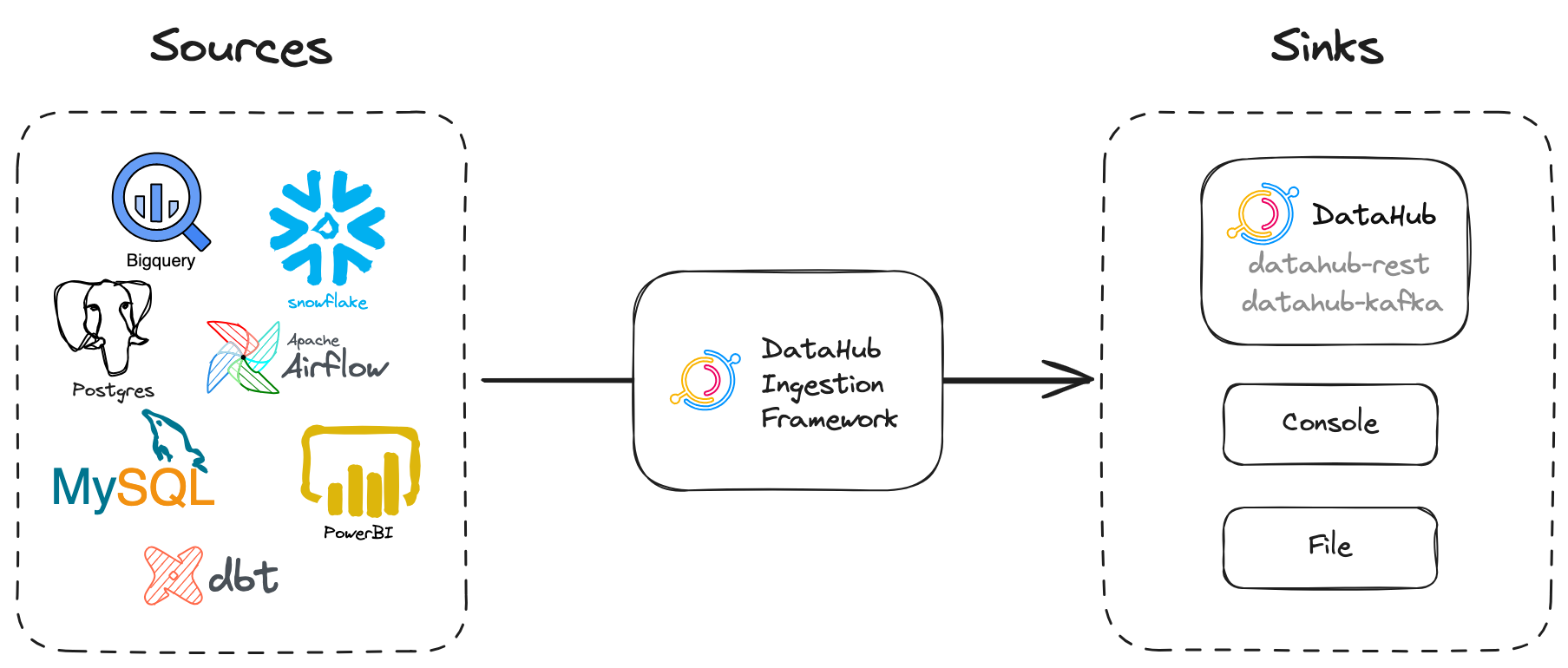
Configuring Recipe
The basic form of the recipe file consists of:
source, which contains the configuration of the data source. (See Sources)sink, which defines the destination of the metadata (See Sinks)
Here's a simple recipe that pulls metadata from MSSQL (source) and puts it into the default sink (datahub rest).
# The simplest recipe that pulls metadata from MSSQL and puts it into DataHub
# using the Rest API.
source:
type: mssql
config:
username: sa
password: ${MSSQL_PASSWORD}
database: DemoData
# sink section omitted as we want to use the default datahub-rest sink
sink:
type: "datahub-rest"
config:
server: "http://localhost:8080"
A number of recipes are included in the examples/recipes directory. For full info and context on each source and sink, see the pages described in the table of plugins.
Note that one recipe file can only have 1 source and 1 sink. If you want multiple sources then you will need multiple recipe files.
Running a Recipe
DataHub supports running recipes via the CLI or UI.
- CLI
- UI
Install CLI and the plugin for the ingestion.
python3 -m pip install --upgrade acryl-datahub
pip install 'acryl-datahub[datahub-rest]'
Running this recipe is as simple as:
datahub ingest -c recipe.dhub.yaml
For a detailed guide on running recipes via CLI, please refer to CLI Ingestion Guide.
You can configure and run the recipe in Ingestion tab in DataHub.

- Make sure you have the Manage Metadata Ingestion & Manage Secret privileges.
- Navigate to Ingestion tab in DataHub.
- Create an ingestion source & configure the recipe via UI.
- Hit Execute.
For a detailed guide on running recipes via UI, please refer to UI Ingestion Guide.
Advanced Configuration
Handling Sensitive Information in Recipes
We automatically expand environment variables in the config (e.g. ${MSSQL_PASSWORD}),
similar to variable substitution in GNU bash or in docker-compose files.
For details, see variable-substitution.
This environment variable substitution should be used to mask sensitive information in recipe files. As long as you can get env variables securely to the ingestion process there would not be any need to store sensitive information in recipes.
Transformations
If you'd like to modify data before it reaches the ingestion sinks – for instance, adding additional owners or tags – you can use a transformer to write your own module and integrate it with DataHub. Transformers require extending the recipe with a new section to describe the transformers that you want to run.
For example, a pipeline that ingests metadata from MSSQL and applies a default "important" tag to all datasets is described below:
# A recipe to ingest metadata from MSSQL and apply default tags to all tables
source:
type: mssql
config:
username: sa
password: ${MSSQL_PASSWORD}
database: DemoData
transformers: # an array of transformers applied sequentially
- type: simple_add_dataset_tags
config:
tag_urns:
- "urn:li:tag:Important"
# default sink, no config needed
Check out the transformers guide to learn more about how you can create really flexible pipelines for processing metadata using Transformers!
Autocomplete and Syntax Validation
Name your recipe with .dhub.yaml extension like myrecipe.dhub.yaml_ to use vscode or intellij as a recipe editor with autocomplete
and syntax validation. Make sure yaml plugin is installed for your editor:
- For vscode install Redhat's yaml plugin
- For intellij install official yaml plugin